The Catch-22 of Business AI
Enterprise AI has a structural catch-22: context lives where you cannot run agents, and compute lives where context does not exist. Move the data and you lose the meaning. That gap is why most deployments produce outputs that are technically impressive and operationally thin.

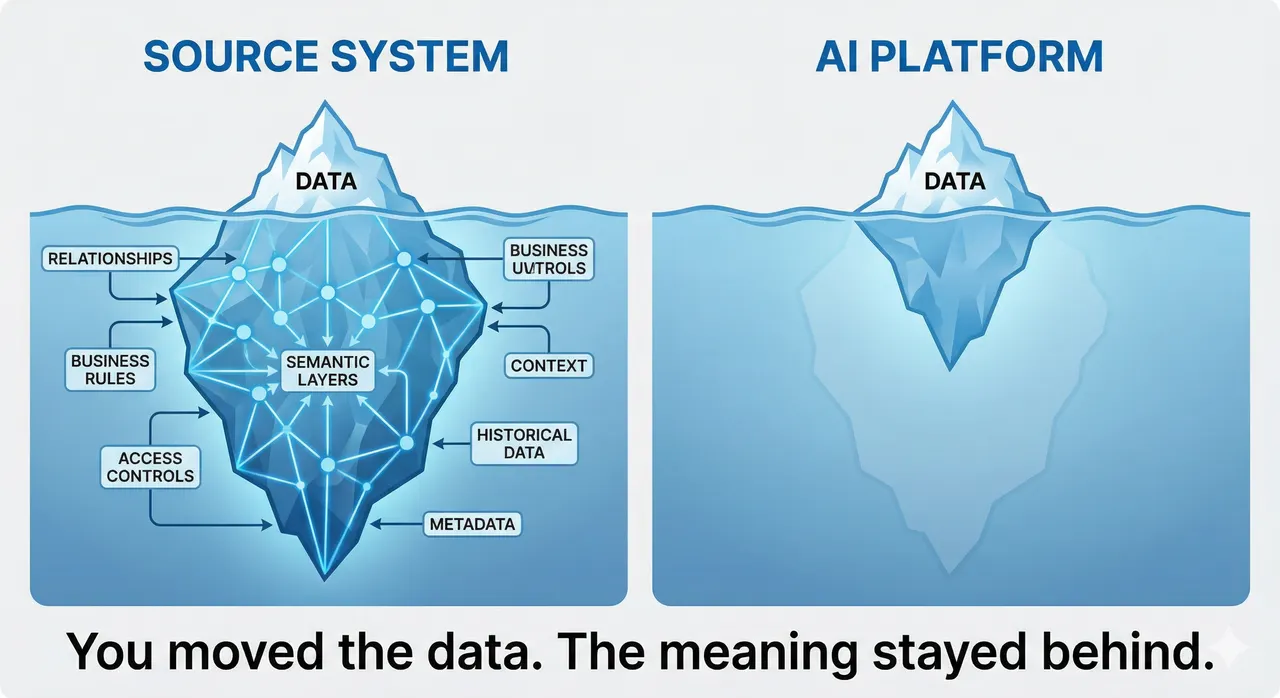
Enterprise AI has a structural problem that does not get talked about enough: the place where business context lives typically cannot run agents, and the place that can run agents does not have the context. Until that gap is closed, enterprise AI will keep producing outputs that are technically impressive and operationally thin.
This is not a model quality problem or a compute cost problem. It is baked into how business data has always worked, and it surfaces in every serious AI deployment that tries to do something useful with operational data.
Context Lives Where You Cannot Run Agents
To understand the catch-22, start with what makes enterprise data valuable in the first place: organic context.
Take a clinical management system like EPIC. When a physician documents a patient encounter, the data that gets created does not live in isolation. It sits inside a web of relationships: the patient's longitudinal history, the care team's prior decisions, the sequence of diagnoses that led to this one, the clinical reasoning that connected one set of symptoms to a treatment plan. None of that context is stored in a single field. It is distributed across the system, embedded in the relationships between records, preserved in the structure of how data was entered and linked over time.
The same logic applies across SAP's enterprise footprint. In S/4HANA's sales order management, a customer order carries the relationship history, the negotiated contract terms, the credit limits shaped by years of payment behavior, and the strategic context that explains why this account receives priority treatment. That meaning is not just in the order record itself. It is in the web of connections surrounding it.
In many SAP implementations, business meaning lives across CDS views, metadata, relationships, and governance rules that explain how fields connect and what they represent. A Customer ID in S/4HANA is not just a number. The semantic layer around it annotates it: this field is a currency, this relationship represents a hierarchy, this formula is how this specific company defines "Net Margin" or "Available-to-Promise" inventory. That business logic is often encoded in CDS views and the surrounding semantic layer, not in the raw database tables.
This context is not always elegantly documented, and it is not always explicit. But it is there, embedded in the system that generated the data, inseparable from the operational logic that produced it.
The problem is that these source systems were not built to run AI. They were built for transactional efficiency: capturing, storing, and retrieving operational data at scale. They can add AI features at the edges, and many are doing exactly that. But they are typically not designed as platforms for autonomous reasoning, cross-functional analysis, or agent orchestration across large and complex datasets.
The Moment Data Leaves, the Story Stays Behind
Organizations respond to this constraint in the most logical way available to them: they move the data to a platform that can run AI. This section explains what gets lost in that move.
Traditional extraction methods, whether standard table replication, generic data lake exports, or CSV pipelines, were designed to move information accurately. They were not designed to move meaning. The fields transfer. The semantic layer rarely does.
What gets stripped in transit falls into three categories, each of which matters independently.
The first is relationships. When you export a Sales Order table from S/4HANA, you get the order. The receiving platform will not automatically know it is linked to a Change Log, a Shipping Constraint table, or a customer credit history. The relational web that made the order meaningful inside the source system has to be reconstructed from scratch, if it gets reconstructed at all.
The second is calculated semantics. The business logic that defines "Customer Churn Risk" or "Available-to-Promise" inventory the way your company specifically calculates it does not live in raw database tables. Export the raw tables and you get numbers. The formulas that give those numbers organizational meaning typically do not travel with them.
The third is security context, and this one is the least discussed. In S/4HANA and EPIC, access controls are not just a compliance layer. They encode operational boundaries about who should reason over which data, reflecting organizational knowledge about whose judgment is relevant to a given decision. When data is exported without that governance context, the AI platform operates without awareness of those distinctions, often reasoning on data that was never intended to be used the way it is now being used.
A 2025 SAP Research survey found that only 34% of business leaders report high trust in their data and AI capabilities [SAP Research, "The Fabric of Data and AI," 2025; n=1,400 data professionals]. That number reflects exactly this gap. The data is accessible. The meaning is not.
Two Paths, Neither Complete
Facing this structural gap, organizations have two options. Neither resolves it fully.
The first path is to embed AI inside the source system, where the context already exists. This preserves the relational web. The AI can see why the lab was ordered, not just the result. It can understand the customer relationship, not just the transaction. Several healthcare technology companies are pursuing this direction with EPIC and similar platforms, building AI features that operate on data that has never left the clinical system.
The limitation is architectural. Source systems were built for a different purpose. Adding AI capabilities inside them is possible at the margin, but running sophisticated agent workflows, orchestrating across multiple data sources, or building organizational intelligence that spans functions and geographies requires a platform architecture that transactional systems were not designed to support. You can add a copilot to a clinical system. Turning that system into an agentic reasoning platform is a different undertaking entirely.
The second path is to move the data to an AI-capable platform and solve the context problem separately. This is where most enterprise AI investment is currently concentrated. The challenge is that preserving meaning in transit is significantly harder than moving data accurately. Data movement is an engineering problem with well-understood solutions. Semantic portability is a design problem that most existing architectures were not built to address.
There is also a scale problem that rarely gets enough attention. Large enterprises generate terabytes of transaction data monthly and retain decades of historical records for regulatory compliance. Moving all of it into centralized stores creates compounding costs: storage multiplies, network bandwidth becomes a bottleneck, and security and compliance exposure increases every time sensitive data replicates across environment boundaries. Data fabric architectures respond to this reality by enabling queries against data where it resides, whether in cloud databases, on-premises systems, or SaaS applications, through federation and intelligent caching rather than extraction. The context problem and the movement problem are distinct issues, but they point in the same direction: the assumption that data must move to be useful is one of the core assumptions enterprise AI architecture needs to rethink.
The consequences of getting this wrong appear in every enterprise domain. When a CFO uses AI to model a workforce reduction, the AI needs to understand which roles are strategically critical, which have long replacement cycles, and where a cut today creates a bottleneck when growth resumes. That context exists in the HR and finance systems. Stripped of it, the AI optimizes for the number it was given. The strategic implications of that optimization are not visible to it.
What a Solution Looks Like
Rethinking what it means to move data is the starting point, not the endpoint.
SAP argues in its Business Data Cloud vision that the right unit of movement is not a table or a file but a data product: data packaged to travel with its business context intact, carrying the semantic layer, the ownership model, the relational logic, and the governance controls that give it meaning in the originating system.
Rather than extracting a field and losing the context, a data product aims to extract the field and the context together. The lab value and the clinical reasoning. The S/4HANA sales order and the customer relationship history that explains it. In SAP's architecture, this means making the CDS layer portable: not just moving the raw tables but moving the annotations, the business rules, the relational definitions, and the access controls alongside them. A semantic layer maintains consistent definitions across functions so that what "employee" means in HR and what it means in finance refer to the same concept, rather than becoming two different numbers that require reconciliation before anyone trusts the output.
SAP's data product approach aims to preserve this context, though implementing portable semantics at enterprise scale remains challenging. The systems that need to supply that context, EPIC, S/4HANA, SAP SuccessFactors, were not designed to expose it in a portable, machine-readable form. Making them do so requires significant work at the source, not just at the destination.
The direction is right: rather than accepting that meaning is lost in transit and trying to compensate downstream, invest in making context portable from the start. The execution is still being built.
What becomes possible when that layer exists extends well beyond solving the context problem. A dedicated Data and AI layer, positioned between source systems and the applications that consume data, creates a platform for capabilities that scattered, movement-based architectures cannot support. Data governance and AI governance can be applied consistently at the layer where context lives, rather than attempted piecemeal at each destination. Context can be actively enriched through knowledge graphs that encode domain relationships and organizational semantics the source systems captured only partially. Integration with dedicated AI platforms like Databricks becomes governed and repeatable rather than ad hoc. And the same enriched, governed, contextualized data can serve multiple consumers simultaneously: agentic AI workflows, analytical dashboards, and operational applications, all drawing from the same foundation. The payoff is not just better AI. It is one version of the truth, properly contextualized, available to every system that needs it.
Why This Is a Product Problem, Not an Infrastructure Problem
The temptation is to frame this as a technical architecture question and hand it to the engineering team. That framing misses what is at stake.
The context that gets stripped when data leaves a source system is not a database field. It is accumulated human knowledge: the decisions, relationships, reasoning, and domain expertise that experienced people carry, and that the system has captured imperfectly but meaningfully over years of operation. When AI reasons without that context, it is not just working from incomplete data. It is reasoning without the institutional knowledge that makes the output trustworthy.
Building AI products that reason with full context is a design obligation, not an infrastructure preference. It requires product teams to ask, before moving any data anywhere, what context that data carries in the source system, what will be lost in transit, and how the AI will account for that loss. Sometimes the answer is to build differently at the source. Sometimes it is to invest in a semantic layer that preserves meaning in transit. Sometimes it is to scope the AI's work to what the available context can actually support.
The catch-22 is not going away on its own. The systems that hold context were not designed for agents, and the platforms designed for agents were not built to hold context. The organizations that close that gap, not by ignoring it but by designing deliberately around it, will build AI that earns the trust most AI deployments have so far only asked for.
The views expressed in this article are my own and do not officially represent the position of SAP or any other organization I am affiliated with.
References: SAP Business Data Cloud, "The Fabric of Data and AI," 2025. SAP Research global survey of 1,400 data professionals, 2025.


