Four Problems. One Root Cause.
New peer-reviewed research named 4 critical challenges blocking healthcare AI deployment. The research got the problems right. But three of those four share one root cause nobody is building toward. One doesn't. Here's the response from the real world.

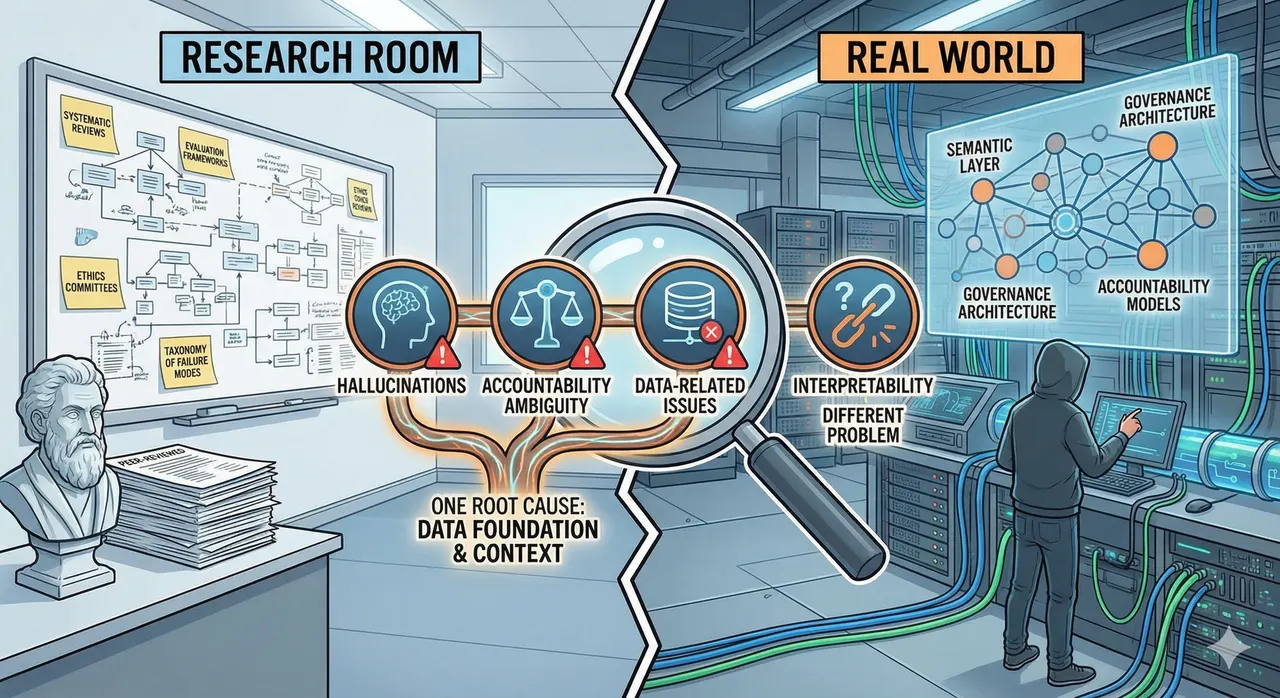
There are two conversations happening about healthcare AI that have not yet found each other.
In the research room: systematic reviews, evaluation frameworks, multi-dimensional metrics, regulatory sandboxes, ethics committees. Rigorous, necessary work. The kind that produces peer-reviewed papers with 81 citations and a proposed taxonomy of failure modes.
In the real world: semantic layers, data harmonization pipelines, governance baked into architecture, accountability models that have to survive contact with real organizations. Unglamorous, operational work. The kind that does not produce papers.
A review published in npj Artificial Intelligence earlier this year is the best thing the research room has produced in some time. It reviewed 81 studies of LLM-based AI agents in healthcare, mapped the application landscape, proposed an evaluation framework, and named four critical challenges blocking deployment. I have spent the past year writing about three of them. What follows is a response from the real world.
What the Paper Found
Zhao et al. identify four challenges that every serious practitioner in healthcare AI has been living with, now named in a peer-reviewed venue with citations across the full landscape of current research.
First, hallucinations, especially in rare-disease and ambiguous clinical presentations, where a model generates confident but incorrect outputs. Not a theoretical concern. A direct patient safety risk in settings where the clinical question is precisely the kind that falls outside the training distribution.
Second, lack of interpretability. Clinicians cannot trace the reasoning chain. This is not a technical nuisance. It is the reason clinical adoption stalls. A physician cannot integrate a recommendation they cannot interrogate. The tool asks for trust it has not earned the right to.
Third, ambiguity in accountability. When AI generates a harmful recommendation, there is no settled legal or ethical framework for assigning responsibility. The disclaimer says "not a substitute for clinical judgment." The patient got the recommendation. The physician signed the note. Who is responsible?
Fourth, data-related issues: training data imbalances across gender, ethnicity, and geography; privacy risks; the absence of robust governance frameworks. The model reflects the data it was trained on. If the data was never representative, the model will not be either, and no evaluation framework applied after the fact will change that.
These are the right problems. They are also not four independent problems.
Three of Four Are the Same Problem
Seen from the real world, these are not distinct technical bugs. They are manifestations of the same design gap: models operating without context. Hallucinations, accountability ambiguity, and data-related failures look like separate issues. They are symptoms of one underlying condition.
Hallucinations increase when there is no grounded context against which to verify outputs. When the data foundation is absent, with no semantic layer, no knowledge graph, no structured business logic linking the model's inputs to verified facts, the model fills the gaps with plausible confabulation. The paper cites retrieval-augmented generation (RAG) and knowledge graphs as mitigations. Correct. It is also an acknowledgment that the context layer is the solution, not a supplement to one.
Accountability ambiguity is not primarily a legal problem. It is an architectural one. When the model's inputs are unverified and its reasoning is untraced, accountability cannot be assigned because the chain of provenance does not exist. There is nothing to audit. Build the right foundation: harmonized data, a documented semantic layer, a traceable decision path. Accountability has a surface to attach to. Without the foundation, an ethics committee is writing policy for a black box.
Data bias, inequity, and privacy risk are governance failures before they are model failures. The model reflects the data it ingested. If that data was never audited for demographic skew, never governed at the ingestion layer, never harmonized across sources with conflicting definitions of the same field, no downstream evaluation will catch what is already baked in. Governance as a post-hoc overlay on unstructured data is documentation for code that was never readable.
From where I sit, building on the data infrastructure layer at SAP Business Data Cloud, this is the daily argument. The organizations deploying AI with any real confidence are not the ones with the best models. They are the ones that did the foundational work first: semantic models that encode business logic, pipelines that preserve provenance, governance built into the architecture rather than added to the presentation layer.
The Walmart case is the clearest public example. When OpenAI's Instant Checkout failed, it did not fail because the model hallucinated or because there was no ethics committee. It failed because the data foundation was not there. The model had no access to the semantic layer that encoded Walmart's operational reality: inventory relationships, pricing logic, substitution rules, supplier context. Once Walmart built that layer, the same category of problem became tractable. Intelligence without context is just confidence.
The paper proposes evaluation frameworks to measure these problems. That is valuable. It is not the starting point. You cannot evaluate your way to trustworthy AI. You have to build the right foundation before evaluation can tell you anything that matters.
The Fourth Problem Is Different
If those three failures share a root cause, the fourth resists the same logic.
Interpretability does not yield to better infrastructure. It is a different kind of problem.
The other three challenges have architectural responses: grounded context reduces hallucinations; traceable data pipelines make accountability possible; governed ingestion prevents bias from compounding. Interpretability is not about what goes into the model or how it is governed. It is about whether the reasoning process is visible to the clinician in a way that supports, rather than displaces, clinical judgment.
The most capable models are often the least interpretable. The architectural choices that produce the best benchmark performance are frequently the ones that produce the most opaque reasoning. Healthcare cannot follow the consumer AI playbook of trusting the output and ignoring the process. The output is a clinical recommendation. The process is how a physician decides whether to act on it.
The paper's proposed Mixture of Experts (MoE) approach, which activates specialized sub-models for specific clinical tasks rather than routing everything through a single general-purpose model, is the most promising architectural direction. It improves performance and improves interpretability simultaneously, by narrowing the scope of what the model is doing at any given moment. A model that is doing one thing is more legible than a model that is doing everything.
But the honest ceiling is this: full interpretability for large language models at clinical scale is not solved. Designing governance frameworks around a capability that does not yet exist is not governance. It is theater. The responsible response is to constrain model autonomy in proportion to interpretability. Where you cannot see the reasoning, keep the human in the loop. Where you can, let the agent act.
What Governance Actually Requires
The paper's fifth future direction is moral and ethical review: the EU AI Act, independent ethics committees, attribution of responsibility. These are necessary conditions. They are not sufficient ones. The failure mode already has a name: governance theater. The committee forms. A charter is written, roles are defined, policies are documented. A year later, the data pipeline producing unverifiable clinical alerts has never been touched. Leadership feels like governance is happening. Clinicians are still closing alerts they cannot trust.
In healthcare specifically, committee-based governance has a structural flaw that makes it worse than theater. Under HIPAA and GDPR, a data steward appointed to oversee clinical data is often legally prohibited from reviewing it without a documented clinical need. The people hired to solve the governance problem cannot look at the data that contains it. This is not a process failure. It is an architectural one, and no governance committee can fix it.
The governance problem in most enterprises is not a capability gap. It is a visibility gap. Data governance and AI governance are the same capability applied to different lifecycle stages: data governance asks whether the data is correct, AI governance asks whether the outcome is acceptable. Same audit trails, quality rules, and access controls; different emphasis, inputs versus outputs. Most organizations already have 70% of what they need for AI governance. They cannot see how their existing data infrastructure connects to the AI accountability requirements now being imposed on them.
The NHS/Google DeepMind case is the instructive example. The failure was not the absence of an ethics committee. There was one. The failure was that the data-sharing architecture preceded the governance architecture. Once patient data had moved, the governance question became retrospective. Retrospective governance is not governance. It is explanation.
What pre-model governance looks like in practice: master data workflows enforcing quality rules before any record reaches the AI layer. A miscategorized material record is not just a reporting error; it trains the demand forecasting model on a flawed assumption. The semantic model is not only a technical artifact. It is a governance artifact. When business logic is encoded explicitly, the governance framework has something concrete to audit before the model ever runs. The committee cannot govern what the pipeline never traced.
What the Research Room and the Real World Need to Say to Each Other
The paper's evaluation framework is the most comprehensive in the published literature. The developmental indicators (efficiency, content quality, humanistic care) push beyond benchmark accuracy toward something that reflects real clinical value. That matters.
What the framework cannot evaluate is what was never built correctly. Measuring a model's outputs against humanistic care indicators when the underlying data is biased produces precise measurements of a biased system. The evaluation is accurate. The foundation is not. The sequence that works is: data architecture, then semantic layer, then governance framework, then model deployment, then evaluation. The sequence most organizations are using ends with the discovery that the data architecture was the problem all along.
The two conversations this article opened with are still not talking to each other. The research community is naming the right problems. Practitioners in the real world have been building partial responses to some of them, without the formal language the research community provides. Both are necessary. Neither has been reading the other's work closely enough.
A governance committee cannot govern what it cannot trace. An evaluation framework cannot measure what was never built. The research community is getting the questions right. The next step is ensuring the people building the foundations are in the room when the answers are designed.
This piece draws on Zhao L et al., "AI agent in healthcare: applications, evaluations, and future directions," npj Artificial Intelligence, 2026;2:31.
For a deeper treatment of the governance spectrum, see "Governance: The Word Everyone Uses and Nobody Agrees On."
For the clinical case against governance theater and why architecture is the only answer that holds up in court, see "Why Healthcare AI Governance Isn't What You Think It Is."


